基于 NVIDIA GPU 加速端点构建 Kimi K2.5 多模态视觉语言模型
Kimi K2.5 是 Kimi 模型家族最新推出的开放式视觉语言模型(VLM)。作为通用型多模态模型,Kimi K2.5 在当前高需求任务中表现出色,涵盖代理式 AI 工作流、对话、推理、编程、数学等领域。
该模型基于开源的 Megatron-LM 框架进行训练。Megatron-LM 通过多种并行策略(包括张量并行、数据并行、序列并行)为大规模 Transformer 模型训练提供加速计算支持,实现可扩展性和 GPU 优化。
该模型架构基于当前领先的尖端大型开放模型构建,兼具高效与能力。模型每层有384个专家,从而支持更小规模的专家及针对不同模态的专用路由机制。Kimi K2.5 实现了每 token 3.2% 的参数激活率。
Kimi K2.5模态文本,图像,视频总参数量1T激活参数量32.86B参数激活率3.2%输入上下文长度262K附加配置信息# 专家数量384# 共享专家数量1# 每个 token 的专家数量8# 层数61 (1 dense, 60 MoE)# 注意力头数量64词汇表大小~164K表1. Kimi K2.5 型号规格与配置详情
在视觉处理能力方面,该模型拥有 16.4 万词的大型训练词汇表,其中包含视觉专属 token。Kimi 为该模型的视觉处理组件设计了 MoonViT3d 视觉塔(vision tower),可将图像和视频帧转换为嵌入向量。
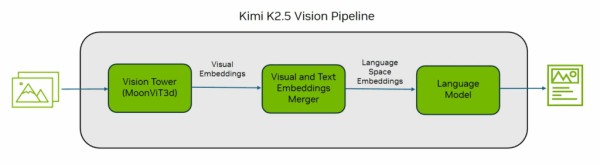
图1. Kimi K2.5视觉管道
基于 NVIDIA GPU 加速的端点进行构建
作为 NVIDIA 开发者计划的一部分,用户可立即使用 Kimi K2.5 开始你 构建。用户可在浏览器环境中使用自有数据。用于生产推理的容器 NVIDIA NIM 微服务即将推出。
视频1. 了解如何在 NVIDIA GPU 加速端点上测试 Kimi K2.5
用户还可以通过 API 使用 NVIDIA 托管的模型,注册 NVIDIA 开发者计划即可免费使用。
import requests invoke_url = "https://integrate.api.nvidia.com/v1/chat/completions" headers = { "Authorization": "Bearer $NVIDIA_API_KEY", "Accept": "application/json", } payload = { "messages": [ { "role": "user", "content": "" } ], "model": "moonshotai/kimi-k2.5", "chat_template_kwargs": { "thinking": True }, "frequency_penalty": 0, "max_tokens": 16384, "presence_penalty": 0, "stream": True, "temperature": 1, "top_p": 1 } # re-use connections session = requests.Session() response = session.post(invoke_url, headers=headers, json=payload) response.raise_for_status() response_body = response.json() print(response_body)
要利用工具调用功能,只需定义一个兼容 OpenAI 的工具数组,将其添加到 chat completions 工具参数中即可。
使用vLLM进行部署
使用 vLLM 服务框架部署模型时,请按照以下说明操作。更多信息请参阅 Kimi K2.5 的 vLLM recipe。
$ uv venv $ source .venv/bin/activate $ uv pip install -U vllm --pre \ --extra-index-url https://wheels.vllm.ai/nightly/cu129 \ --extra-index-url https://download.pytorch.org/whl/cu129 \ --index-strategy unsafe-best-match
使用 NVIDIA NeMo 框架进行微调
Kimi K2.5 可通过开源的 NeMo 框架进行定制与微调,借助 NeMo AutoModel 库将模型适配于特定领域的多模态任务、智能体工作流及企业推理场景。
NeMo 框架是一套开源库集合,支持可扩展的模型预训练与后训练,涵盖监督性微调、参数高效方法,及适用于各种规模和模态的模型的强化学习。
NeMo AutoModel 是 NeMo 框架内原生的 PyTorch 分布式训练库,支持直接在 Hugging Face 检查点上进行高吞吐量训练,无需进行转换操作。该工具为开发者和研究人员提供了轻量且灵活的解决方案,助力其在最新前沿模型上快速开展实验。
尝试使用 NeMo AutoModel recipe 对 Kimi K2.5 进行微调。
开始使用 Kimi K2.5
从基于 NVIDIA Blackwell 的数据中心部署到全托管的企业级 NVIDIA NIM 微服务,NVIDIA 提供了多种方案以便集成 Kimi K2.5 集。立即访问Hugging Face 平台的 Kimi K2.5 模型页面及 Kimi API 平台。
关于作者
网址:基于 NVIDIA GPU 加速端点构建 Kimi K2.5 多模态视觉语言模型 https://m.mxgxt.com/news/view/2002401
相关内容
明星项目Quai Network全节点+GPU搭建全攻略NVIDIA 与合作伙伴共同发布面向企业应用全新开放获取大数据模型
阿里推出Ovis2.5:多模态大语言模型的又一重要突破
nvidia是什么品牌,mate20x?
火速围观!Trae IDE 迎来两大明星模型,Kimi K2 硬核登场,Grok
英伟达NVIDIA:Computex 2025期间发布关键技术 向开放生态平台转型
kimi chat大模型的200万长度无损上下文可能是如何做到的?
Kimi爆火,谁制造了大模型的又一次狂欢?
StarVector:图像秒变矢量代码!开源多模态模型让SVG生成告别手绘
CES 2026:AI终于从“功能点”变成“产品架构”
随便看看
最新实时动态
- 1997年泰坦尼克号横空出世,诠释真爱与生命的经典
- 谍战剧:特务老K隐藏颇深,坏事做尽,地下党终于逮到机会了
- i-dle 新单 官方MV新预告释出 迷你九辑《We made》将于7月6号发行
- 张艺兴新专辑斗战胜佛吉隆坡震撼亮相
- 好喜欢张婧仪的笑
- 想象坐在台下静静听他唱完整首国风曲,氛围感温柔绵长,幸福感爆棚
- 亲临现场听他唱歌太治愈,旋律与歌声相融,全程幸福感拉满
- 把我当成她,可是致命的弱点哦
- 妼晗深情告白仁宗,别无他求唯有喜欢
- 黑老大怎么也没想到,自己要杀的人,竟是自己的女儿!
热点实时动态
- 103170
- 25300
- 19902
- 19581
- 19349
- 19307
- 19046
- 18610
- 18572
- 18561

