【推荐系统】基于标签的推荐算法(SimpleTagBased,NormTagBased,TagBased
本篇主要介绍基于标签的推荐算法,涉及了3个原理较简单的计算方法(Simple Tag-based、Normal Tag-based、Tag-based-Tfidf ),以及python代码实现。
1.概述
1.1 如何定义用户画像
用户画像即是对用户行为特征的总结归纳和描述,以更好的提升业务质量。
用户画像的关键步骤:
1.2 如何给用户打标签
用户画像 即描述用户的行为特征,可抽象为标签。 那么如何给用户打标签呢?
典型的方式有:
PGC:专家生产,通过工作人员进行打标签(质量高,数据规范) UGC:用户生产 (质量低,数据不规范)标签是对高维事物的抽象(降维),所以可以利用聚类、降维的方法进行物品标签的生成。目前主流的聚类方法有:Kmeans,EM,DBScan,层级聚类,PCA等等。
1.3 如何给用户推荐标签
当用户u给物品i打标签时,可以给用户推荐和物品i相关的标签,方法如下:
方法1:给用户u推荐整个系统最热门的标签 方法2:给用户u推荐物品i上最热门的标签 方法3:给用户u推荐他自己经常使用的标签 将方法2和3进行加权融合,生成最终的标签推荐结果2.基于标签的算法
2.1 Simple Tag-based
其中 user_tags[u,t] 表示【用户u使用标签t的次数】,tag_items[t, i] 表示【物品i被打上标签t的次数】
2.2 Norm Tag-based
Simple Tag-based 使用次数的绝对值,在很多情况下不能真实的反映用户的个性化需求。 比如可能某个用户尤其喜欢打标签,所以本身打标签的次数就比较多,或者某个标签可能非常热门,可能每个物品都打上这个热门标签,导致最终的score很大。 因此对Simple Tag-based 做归一化改进,即Norm Tag-based 算法。
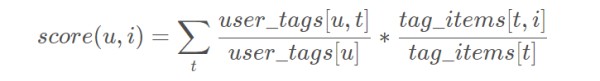
其中 user_tags[u] 表示【用户u打标签的总次数】,tag_items[t] 表示【标签t被使用的总次数】
2.3 Tag-based TFIDF
同样的,如果一个tag很热门,会导致给热门标签过大的权重,不能反应用户个性化的兴趣。
TF-IDF的定义:
TF:Term Frequency,词频=单词次数/文档中总单词数
一个单词的重要性和它在文档中出现的次数呈正比
IDF:Inverse Document Frequency,逆向文档频率=log(文档总数/(单词出现的文档数+1))
一个单词在文档中的区分度。这个单词出现的文档数越少,区分度越大,IDF越大
这里借鉴TF-IDF的思想,使用tag_users[t]表示标签t被多少个不同的用户使用

3.代码实现
基本结构的定义:
用户打标签的记录【user_id, item_id, tag】 用户打过的标签【user_id, tag】 用户打过标签的item【user_id, item】 打上某标签的item【tag, item】 同样打过某标签的用户【tag, user_id】# 使用SimpleTagBased算法对Delicious2K数据进行推荐 # 原始数据集:https://grouplens.org/datasets/hetrec-2011/ # 数据格式:userID bookmarkID tagID timestamp import random import math import operator import pandas as pd file_path = "./user_taggedbookmarks-timestamps.dat" # 字典类型,保存了user对item的tag,即{userid: {item1:[tag1, tag2], ...}} records = {} # 训练集,测试集 train_data = dict() test_data = dict() # 用户标签,商品标签 user_tags = dict() tag_items = dict() user_items = dict() # 使用测试集,计算精确率和召回率 def precisionAndRecall(N): hit = 0 h_recall = 0 h_precision = 0 for user,items in test_data.items(): if user not in train_data: continue # 获取Top-N推荐列表 rank = recommend(user, N) for item,rui in rank: if item in items: hit = hit + 1 h_recall = h_recall + len(items) h_precision = h_precision + N #print('一共命中 %d 个, 一共推荐 %d 个, 用户设置tag总数 %d 个' %(hit, h_precision, h_recall)) # 返回准确率 和 召回率 return (hit/(h_precision*1.0)), (hit/(h_recall*1.0)) # 对单个用户user推荐Top-N def recommend(user, N): recommend_items=dict() # 对Item进行打分,分数为所有的(用户对某标签使用的次数 wut, 乘以 商品被打上相同标签的次数 wti)之和 tagged_items = user_items[user] for tag, wut in user_tags[user].items(): #print(self.user_tags[user].items()) for item, wti in tag_items[tag].items(): if item in tagged_items: continue #print('wut = %s, wti = %s' %(wut, wti)) if item not in recommend_items: recommend_items[item] = wut * wti else: recommend_items[item] = recommend_items[item] + wut * wti return sorted(recommend_items.items(), key=operator.itemgetter(1), reverse=True)[0:N] # 使用测试集,对推荐结果进行评估 def testRecommend(): print("推荐结果评估") print("%3s %10s %10s" % ('N',"精确率",'召回率')) for n in [5,10,20,40,60,80,100]: precision,recall = precisionAndRecall(n) print("%3d %10.3f%% %10.3f%%" % (n, precision * 100, recall * 100)) # 数据加载 def load_data(): print("开始数据加载...") df = pd.read_csv(file_path, sep='\t') for i in range(len(df)): uid = df['userID'][i] iid = df['bookmarkID'][i] tag = df['tagID'][i] # 键不存在时,设置默认值{} records.setdefault(uid,{}) records[uid].setdefault(iid,[]) records[uid][iid].append(tag) print("数据集大小为 %d." % (len(df))) print("设置tag的人数 %d." % (len(records))) print("数据加载完成\n") # 将数据集拆分为训练集和测试集 def train_test_split(ratio, seed=100): random.seed(seed) for u in records.keys(): for i in records[u].keys(): # ratio比例设置为测试集 if random.random()<ratio: test_data.setdefault(u,{}) test_data[u].setdefault(i,[]) for t in records[u][i]: test_data[u][i].append(t) else: train_data.setdefault(u,{}) train_data[u].setdefault(i,[]) for t in records[u][i]: train_data[u][i].append(t) print("训练集样本数 %d, 测试集样本数 %d" % (len(train_data),len(test_data))) # 设置矩阵 mat[index, item] = 1 def addValueToMat(mat, index, item, value=1): if index not in mat: mat.setdefault(index,{}) mat[index].setdefault(item,value) else: if item not in mat[index]: mat[index][item] = value else: mat[index][item] += value # 使用训练集,初始化user_tags, tag_items, user_items def initStat(): records=train_data for u,items in records.items(): for i,tags in items.items(): for tag in tags: #print tag # 用户和tag的关系 addValueToMat(user_tags, u, tag, 1) # tag和item的关系 addValueToMat(tag_items, tag, i, 1) # 用户和item的关系 addValueToMat(user_items, u, i, 1) print("user_tags, tag_items, user_items初始化完成.") print("user_tags大小 %d, tag_items大小 %d, user_items大小 %d" % (len(user_tags), len(tag_items), len(user_items))) # 数据加载 load_data() # 训练集,测试集拆分,20%测试集 train_test_split(0.2) initStat() testRecommend()
开始数据加载... 数据集大小为 437593. 设置tag的人数 1867. 数据加载完成 训练集样本数 1860, 测试集样本数 1793 user_tags, tag_items, user_items初始化完成. user_tags大小 1860, tag_items大小 36884, user_items大小 1860 推荐结果评估 N 精确率 召回率 5 0.829% 0.355% 10 0.633% 0.542% 20 0.512% 0.877% 40 0.381% 1.304% 60 0.318% 1.635% 80 0.276% 1.893% 100 0.248% 2.124%
参考链接:https://blog.csdn.net/weixin_41578567/article/details/110049018
网址:【推荐系统】基于标签的推荐算法(SimpleTagBased,NormTagBased,TagBased https://m.mxgxt.com/news/view/1966422
相关内容
电影推荐系统中基于图的协同过滤算法基于协同过滤算法的电影推荐系统及相关电影数据挖掘
一种基于追星族公会的大数据智能推荐系统及方法与流程
基于知识图谱的内容推荐算法研究与实现
京东的个性化推荐系统
用户画像生成及个性化推荐算法
智能推荐中的文本挖掘算法详解
跨平台的音乐推荐算法【2】
智能算法优化娱乐内容个性化推荐系统研究
众星北斗申请基于用户画像的礼物推荐方法及系统专利,生成个性化的礼物推荐列表
随便看看
最新实时动态
- 果郡王闻甄嬛或远嫁和亲,贸然闯殿印证皇帝疑心
- 古惑仔最后一部!年少时看江湖义气,成年后看权谋人心
- 少年一时的兴起,换来忠犬至死不渝守候
- 正是憋不住笑的年纪
- 导演为了效果炸死功勋军犬,辅导员当场哭到崩溃,网友怒打一星
- 陈少熙不立人设不伪装,凭真诚圈粉无数
- 台湾粉丝镜头前夸肖战:人间清醒、自律情商高,从陈情令一路追到现在,cr.
- 油缸里的西瓜,滑不溜手、软硬不吃
- 俩女儿同时亲妈妈,看她会先看向谁,网友:我也俩女儿!
- 所以在X乐园里玩了什么呢
热点实时动态
- 136914
- 25513
- 20104
- 19795
- 19539
- 19496
- 19234
- 18802
- 18780
- 18754

