转载
阿里云AI实训营电商专题「电商人爆款打造攻略」课程上新!第二期课程由设计领域头部AI博主「来真的」教你在阿里云百炼上用Wan2.5-Preview生成电商服饰设计图,零基础也能玩转AI服饰设计,点击链接立即学习!还有tokens超值优惠包,最低20元可抵千万tokens! 立即点击链接,观看课程: https://click.aliyun.com/m/1000408193/
当我们知道影片的发行日期规律、发行国分布规律之后,很自然地,我们就会想要知道在这些影片当中,最受欢迎的影视明星有哪些。不过稍微有丢丢遗憾的是:如同在分析影片发行国分布规律中所遭遇的那种隐藏在内心深处的爱国情怀的影响那样,我们这里分析最受欢迎的明星时,大概率依然会以华人明星占据大多数。估计要是外国佬看了,肯定就会噘嘴不服气,哈哈哈。
star = '' for i in range(100): star = star + data.iloc[i,1] + ',' author = star.split(',') #这里采用的是collections库中的Counter()函数 #它可以很快速地帮我们统计出不同数据出现的次数 star_count = Counter(author) #然后就可以得出次数最多的6个数据,也就是6个明星 #当然,你也可以选择出现次数最多的10个明星或者20个都可以 count = star_count.most_common(6) attr_author = [] v_author = [] for i in count: attr_author.append(i[0]) v_author.append(i[1]) bar = ( Bar() .add_xaxis(attr_author) .add_yaxis('',v_author) .set_global_opts(title_opts=opts.TitleOpts(,pos_left='center')) ) bar.render_notebook()1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.20.21.22.
其运行结果如下:
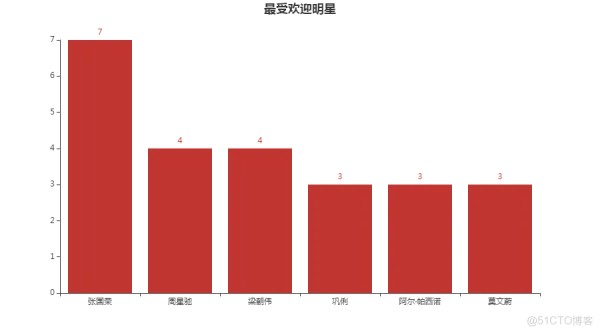
从这个柱状图来看,张国荣、周星驰、梁朝伟等中国明星更加受欢迎一些。毕竟他们大都出现在了由我们国家所发行的那些大片中。而且他们的演技也确实得到了观众的认可,不然也不会有这么明显的受欢迎度。
贰
不同影评分区间影片占比
最后,我们感兴趣的是,这100部大片中,其影评分大致是一个什么样的分布规律呢?因为从一个影评分分布规律中我们可以很清楚地看出,大部分影片的一个受欢迎程度。
#本段小代码的主要作用是分析不同评分区间的影片数占比 score = data.groupby('star')['star'].count() #求出最大影评分和最小影评分,为对电影评分划分区间做准备 score_min = data['star'].min() score_max = data['star'].max() bins = [score_min-1,9.0,9.2,9.4,score_max+1] labels=['9.0分以下','9.0分-9.2分之间','9.2分-9.4分之间','9.4分以上'] score_df = pd.cut(data['star'],bins=bins, labels=labels) #获得不同电影评分区间的影片数量分布 data['得分分布']=score_df score_count = data.groupby('得分分布')['star'].agg({'数量':np.size}) #获得不同影片评分区间的影片数 labels_count = score_count['数量'].to_numpy() pie1 = Pie() pie1.add( "电影评分", [list(z) for z in zip(labels,labels_count)], # center为圆心坐标 center=["20%", "50%"], # 60为内半径,80为外半径 radius=[60, 80], ) pie1.set_global_opts( title_opts=opts.TitleOpts(,pos_left='left'), legend_opts=opts.LegendOpts( type_="scroll", pos_top="200%", pos_left="80%", orient="vertical" ), ) # 设置显示百分比 pie1.set_series_opts( tooltip_opts=opts.TooltipOpts( trigger="item", formatter="{a} {b}: {c} ({d}%)" )) pie1.render_notebook()1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.20.21.22.23.24.25.26.27.28.29.30.31.32.33.34.
其代码运行结果如下:

从这个饼状图中,我们不难看出,即便是被选择出来的100部最受欢迎的大片。其中大部分的影片得分都在9.2分以下,占比在9.2分~9.4分之间的已经很少,而超过9.4分的影片则是占比更加稀少。不知道是因为观众的审美标准越来越严格还是这些大片的制作水准有些下降。但我想,这个影评分占比示意图或许可以给一些大片制作者们一个客观的分析依据。没准当我们有一天进一步爬取更多的影片数据,比如影片的评论数据时,我们还可以基于这个影评分饼状图,结合影片评论的文本数据分析,得出影片评分高的原因都有哪些,不高的原因又有哪些。
叁
总结
对猫眼Top100电影数据的分析,其难度并不大。至少不会比我们即将要介绍的另一个项目案例——基于链家的二手房数据分析项目案例要复杂。
不过,麻雀虽小五脏俱全。我们通过这样一个生动的实际项目案例,就能够完整地体会到:
1、一个很完整的Python数据分析的套路都包含哪些环节;
2、如何将我们所学习到的具体数据分析手段、技巧等应用到一个具体的数据分析项目案例当中;
3、充分发动大脑的运转,还能够学到一点点其他的Python模块知识,比如这里的pyecharts和collections库等。这里顺带留个小悬念供大家去思考去实践:如果我们在分析不同年份下的影片上映数时,采用的是Matplotlib库来做可视化展示,大家感觉会有什么样的一些不同?对我们的分析结论的解释会不会起到更好的帮助?
4、除了要学会数据分析这门硬功夫之外,我们还需要掌握一点社会上其他方面的知识,比如与电影相关的一些常识等。要不然当需要你来解释这些分析结论时,你若只能说从这些图中可以看出什么什么之类的话,那你的价值就会被大打折扣了。因此,从这个角度来看,数据分析师真的就是一个综合能力要求极高的职业。如果我们真的具备了这方面的综合能力,相信大家借此去找一份高新工作,一定不会太难。
5、数据的来源非常重要,因为它往往能够决定数据表述的完整性。我们在这里的猫眼Top100电影数据集中,所得到的影片国家信息就是不怎么完整的。因为有的影片没有获得国家信息,但凭借着我们在代码中的处理,就将其统一归类于中国。可实际上它们很可能是一部部外国大片,比如泰坦尼克号这部大片,就因为没有在爬取过程中没有获得完整的国家信息,故而被错误划分为国产大片。因此,从这个角度来看,数据分析对数据的来源要求也是非常高的。再往深一点说,就要求我们在获取数据时要尽可能确保数据表述的完整性。如果我们使用的是爬虫技术来爬取数据,就要求我们的爬虫功底要足够深厚,要不真的会给后面的数据分析带来很大的麻烦,直接影响到最终分析结论的准确性。
总之,一个简单的数据分析项目案例,就带我们完整地走完了一遍数据分析的旅程,同时也多少收获到了一点数据分析技术之外的小技巧和小心得。
阿里云AI实训营电商专题「电商人爆款打造攻略」课程上新!第二期课程由设计领域头部AI博主「来真的」教你在阿里云百炼上用Wan2.5-Preview生成电商服饰设计图,零基础也能玩转AI服饰设计,点击链接立即学习!还有tokens超值优惠包,最低20元可抵千万tokens! 立即点击链接,观看课程: https://click.aliyun.com/m/1000408193/
本文章为转载内容,我们尊重原作者对文章享有的著作权。如有内容错误或侵权问题,欢迎原作者联系我们进行内容更正或删除文章。
赞 收藏 评论 举报相关文章

