【python爬虫课程设计】NBA球队数据——绘制球员数据柱状图和词云
一、选题的背景
1.背景:随着人们越来越热爱体育运动,NBA(美国职业篮球联赛)体育赛事就是在这一大背景下应运而生的随着时间的推移NBA新的赛季也开始了。
2.目的:为了分析赛程对某-支球队的利弊,我们考虑的因素主要有每支球队两场比赛之间的场次总数、平均相隔场数、背靠背打比赛、球队实力、休息日,并根据这些因素将赛程转换为便于进行数学处理的数字格式,最后给出评价赛程利弊的数量指标。
二、主题式网络爬虫设计方案
1.主题式网络爬虫名称
【python爬虫课程设计】NBA球队数据——绘制球员数据柱状图和词云
2.主题式网络爬虫爬取的内容与数据特征分析
爬取相关球员数据,包含球队,位置,出场时间,投篮次,命中次数等。并通过数据可视化表现出来。
3.主题式网络爬虫设计方案概述(包括实现思路与技术难点)
实现思路: 1. 数据采集。具体来源于
http://www.stat-nba.com/query.php?page=#page#&QueryType=ss&SsType=season&AT=avg&order=1&crtcol=pts&PageNum=150&Season0=1950&Season1=2020
2. 进行数据的清洗,对需要的数据进行定位和提取,并进行存取。
3. 传入数据,绘制词云和进一步数据可视化。
技术难点:1.节点的寻找。
2.数据可视化的灵活运用
三、主题页面的结构特征分析
1.寻找所需的数据。登录网站,右键网络源代码。

2.数据清洗
对所需的库进行导入:
import time
import pandas as pd
import requests
from lxml import etree
import openpyxl
from matplotlib import pyplot as plt
from pyecharts.charts import Bar
from pyecharts.globals import ThemeType
from pyecharts import options as opts
import shelve # 引入shelve做数据持久化
import seaborn as sns
from wordcloud import WordCloud
爬虫主要代码
# 获取数据
url = "http://www.stat-nba.com/query.php?page=#page#&QueryType=ss&SsType=season&AT=avg&order=1&crtcol=pts&PageNum=150" \
"&Season0=1950&Season1=2020 "
res = requests.get(url.replace('#page#', '0'))
html = etree.HTML(res.content)
total_count = int(html.xpath('//*[@id="label_show_result"]/div[3]/div[2]/text()')[1])
# 总页数
total_page = int(total_count / 150) + 1
print("开始获取,共%d条,分%d页数据" % (total_count, total_page))
wb = openpyxl.Workbook()
ws = wb.active
ws.title = "NBA历届球员数据榜"
ws.append(
["球员", "赛季", "球队", "出场", "首发", "时间", "投篮", "命中", "出手", "三分", "命中", "出手",
"罚球", "命中", "出手", "篮板", "前场", "后场", "助攻", "抢断", "盖帽", "失误", "犯规",
"得分", "胜场", "负场"])
for j in range(4):
for i in range(20):
query_url = url.replace("#page#", str(i))
res = requests.get(query_url)
page_html = etree.HTML(res.content)
table = page_html.xpath('//*[@id="label_show_result"]/div[2]/table/tbody')
while len(table) == 0: # 如果访问失败 延时3S 重新获取
print("第%d页数据获取失败,重新获取" % i)
time.sleep(10)
res = requests.get(query_url)
page_html = etree.HTML(res.content)
table = page_html.xpath('//*[@id="label_show_result"]/div[2]/table/tbody')
for row in table[0].getchildren():
td_list = row.getchildren()
temp_list = []
for td in td_list:
td_children = td.getchildren()
if len(td_children) > 0:
temp_list.append(td_children[0].text)
else:
temp_list.append(td.text)
temp_list.pop(0)
ws.append(temp_list)
print("工作表行数:%d", ws.max_row)
wb.save('nba.data.xlsx')
运行后:
打开文件: 22-23赛季世界顶级联赛球员数据表
绘制wordcloud
球员得分
wb = openpyxl.load_workbook('nba.data.xlsx')
ws = wb.active
def create_cloud(frequency, name):
wordcloud = WordCloud(font_path="C:/Windows/Fonts/simsun.ttc",
background_color="white",
width=2021, height=1080)
# 根据数据数目生成词云
wordcloud.generate_from_frequencies(frequency)
# 保存词云
wordcloud.to_file('%s.png' % name)
frequency_score = {}
for row in ws.values:
if row[0] == "排行":
pass
else:
frequency_score[row[1]] = float(row[24])
生成png图片
球员得分词云

球员篮板数
frequency_backboard = {}
for row in ws.values:
if row[0] == "排行":
pass
else:
if row[16].isspace():
frequency_backboard[row[1]] = 0
else:
frequency_backboard[row[1]] = float(row[16])
create_cloud(frequency_score, "球员得分情况词云图")
create_cloud(frequency_backboard, "球员篮板数词云图 ")
df = db = shelve.open("store")
df = db.get("data")
生成png图片
球员篮板词云

3. 数据可视化
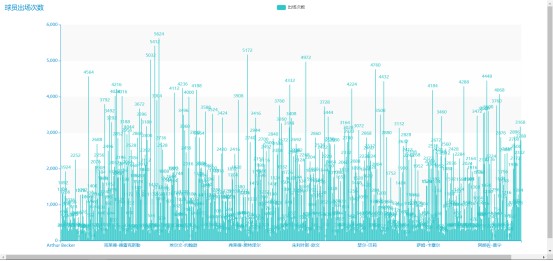
df2 = df.groupby('球员')[['出场']].sum().reset_index()
players = df2['球员'].values.tolist()
ext = df2['出场'].values.tolist()
bar = (
Bar({"theme": ThemeType.MACARONS, "width": "1600px", "height": "720px"})
.add_xaxis(players)
.add_yaxis("出场次数", ext)
.set_global_opts(
title_opts={"text": "球员出场次数"}
)
# 生成html文件
.render("player_exit.html")
)
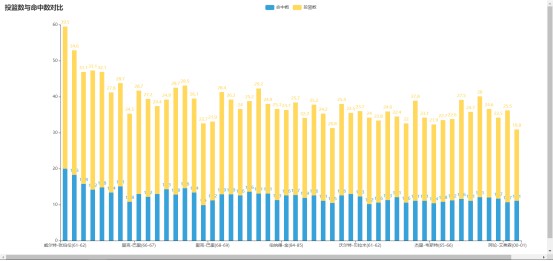
# 生成球员(赛季)投篮出手与命中对比图
df3 = df
# 合并球员与赛季
df3['球员(赛季)'] = df3['球员'].map(str) + '(' + df['赛季'].map(str) + ')'
players = df3["球员(赛季)"].values.tolist()
shoot = df3['出手'].values.tolist()
hit = df3['命中'].values.tolist()
bar1 = (
Bar({"theme": ThemeType.MACARONS, "width": "1600px", "height": "720px"})
.add_xaxis(players)
.add_yaxis("投篮数", shoot, stack="stack1", category_gap="50%")
.add_yaxis("命中数", hit, stack="stack1", category_gap="50%")
# 生成文件
.set_global_opts(
title_opts={"text": "投篮数与民众数对比"}
)
.render("球员投篮数与命中数对比.html")
)
# 生成前50条
bar2 = (
Bar(init_opts=opts.InitOpts(theme=ThemeType.LIGHT, width="1600px", height="720px"))
.add_xaxis(players[0:50])
.add_yaxis("命中数", hit[0:50], stack="stack1", category_gap="50%")
.add_yaxis("投篮数", shoot[0:50], stack="stack1", category_gap="50%")
# 生成文件
.set_global_opts(
title_opts={"text": "投篮数与命中数对比"}
)
.render("球员投篮数与命中数对比(前50条).html")
)
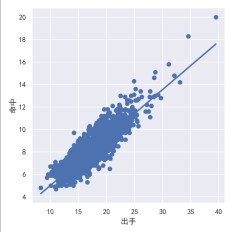
# 绘制投篮出手与命中回归线
# 从持久化中获取数据
db = shelve.open("store")
plt_data = db.get("data")
plt_data.head()
sns.set()
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.grid()
sns.lmplot(x='出手', y='命中', data=plt_data)
plt.savefig("球员投篮出手与命中的回归.png", dpi=300)
投篮数与命中数对比
球员出场次数
球员投篮出手与命中率回归
四、附完整程序源代码
import time
import pandas as pd
import requests
from lxml import etree
import openpyxl
from matplotlib import pyplot as plt
from pyecharts.charts import Bar
from pyecharts.globals import ThemeType
from pyecharts import options as opts
import shelve # 引入shelve做数据持久化
import seaborn as sns
from wordcloud import WordCloud
# 获取数据
url = "http://www.stat-nba.com/query.php?page=#page#&QueryType=ss&SsType=season&AT=avg&order=1&crtcol=pts&PageNum=150" \
"&Season0=1950&Season1=2020 "
res = requests.get(url.replace('#page#', '0'))
html = etree.HTML(res.content)
total_count = int(html.xpath('//*[@id="label_show_result"]/div[3]/div[2]/text()')[1])
# 总页数
total_page = int(total_count / 150) + 1
print("开始获取,共%d条,分%d页数据" % (total_count, total_page))
wb = openpyxl.Workbook()
ws = wb.active
ws.title = "NBA历届球员数据榜"
ws.append(
["球员", "赛季", "球队", "出场", "首发", "时间", "投篮", "命中", "出手", "三分", "命中", "出手",
"罚球", "命中", "出手", "篮板", "前场", "后场", "助攻", "抢断", "盖帽", "失误", "犯规",
"得分", "胜场", "负场"])
for j in range(4):
for i in range(20):
query_url = url.replace("#page#", str(i))
res = requests.get(query_url)
page_html = etree.HTML(res.content)
table = page_html.xpath('//*[@id="label_show_result"]/div[2]/table/tbody')
while len(table) == 0: # 如果访问失败 延时3S 重新获取
print("第%d页数据获取失败,重新获取" % i)
time.sleep(10)
res = requests.get(query_url)
page_html = etree.HTML(res.content)
table = page_html.xpath('//*[@id="label_show_result"]/div[2]/table/tbody')
for row in table[0].getchildren():
td_list = row.getchildren()
temp_list = []
for td in td_list:
td_children = td.getchildren()
if len(td_children) > 0:
temp_list.append(td_children[0].text)
else:
temp_list.append(td.text)
temp_list.pop(0)
ws.append(temp_list)
print("工作表行数:%d", ws.max_row)
wb.save('nba.data.xlsx')
# 将数据转成np.dataframe并持久化
data = pd.read_excel('nba.data.xlsx')
db = shelve.open('store')
db['data'] = data
db.close()
# 生成词云---球员得分
wb = openpyxl.load_workbook('nba.data.xlsx')
ws = wb.active
def create_cloud(frequency, name):
wordcloud = WordCloud(font_path="C:/Windows/Fonts/simsun.ttc",
background_color="white",
width=2021, height=1080)
# 根据数据数目生成词云
wordcloud.generate_from_frequencies(frequency)
# 保存词云
wordcloud.to_file('%s.png' % name)
frequency_score = {}
for row in ws.values:
if row[0] == "排行":
pass
else:
frequency_score[row[1]] = float(row[24])
# 生成词云 -- 球员篮板数
frequency_backboard = {}
for row in ws.values:
if row[0] == "排行":
pass
else:
if row[16].isspace():
frequency_backboard[row[1]] = 0
else:
frequency_backboard[row[1]] = float(row[16])
create_cloud(frequency_score, "球员得分情况词云图")
create_cloud(frequency_backboard, "球员篮板数词云图 ")
df = db = shelve.open("store")
df = db.get("data")
# 生成球员与出场次数柱状图
# 按球员名称分组并将出场数相加
df2 = df.groupby('球员')[['出场']].sum().reset_index()
players = df2['球员'].values.tolist()
ext = df2['出场'].values.tolist()
bar = (
Bar({"theme": ThemeType.MACARONS, "width": "1600px", "height": "720px"})
.add_xaxis(players)
.add_yaxis("出场次数", ext)
.set_global_opts(
title_opts={"text": "球员出场次数"}
)
# 生成html文件
.render("player_exit.html")
)
# 生成球员(赛季)投篮出手与命中对比图
df3 = df
# 合并球员与赛季
df3['球员(赛季)'] = df3['球员'].map(str) + '(' + df['赛季'].map(str) + ')'
players = df3["球员(赛季)"].values.tolist()
shoot = df3['出手'].values.tolist()
hit = df3['命中'].values.tolist()
bar1 = (
Bar({"theme": ThemeType.MACARONS, "width": "1600px", "height": "720px"})
.add_xaxis(players)
.add_yaxis("投篮数", shoot, stack="stack1", category_gap="50%")
.add_yaxis("命中数", hit, stack="stack1", category_gap="50%")
# 生成文件
.set_global_opts(
title_opts={"text": "投篮数与民众数对比"}
)
.render("球员投篮数与命中数对比.html")
)
# 生成前50条
bar2 = (
Bar(init_opts=opts.InitOpts(theme=ThemeType.LIGHT, width="1600px", height="720px"))
.add_xaxis(players[0:50])
.add_yaxis("命中数", hit[0:50], stack="stack1", category_gap="50%")
.add_yaxis("投篮数", shoot[0:50], stack="stack1", category_gap="50%")
# 生成文件
.set_global_opts(
title_opts={"text": "投篮数与命中数对比"}
)
.render("球员投篮数与命中数对比(前50条).html")
)
# 绘制投篮出手与命中回归线
# 从持久化中获取数据
db = shelve.open("store")
plt_data = db.get("data")
plt_data.head()
sns.set()
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.grid()
sns.lmplot(x='出手', y='命中', data=plt_data)
plt.savefig("球员投篮出手与命中的回归.png", dpi=300)
五、总结
1.总结
通过本次的课程设计学习,我们可以清晰的了解到NBA球员和各个球队的整体实力。
2.目标
已经达到我预期的目标。通过对爬取的数据进行数据可视化分析,可以较便捷得看出那个球队具有获得冠军的实力。
3.自我建议
(1)加强自身独立自主的能力,提高编程技能。在本次课程设计中,询问了室友许多的内容。自己在编程上的功底薄弱,有待加强。
(2)多逛csdn等编程学习平台,扎实自身,并打开视野。
网址:【python爬虫课程设计】NBA球队数据——绘制球员数据柱状图和词云 https://m.mxgxt.com/news/view/1535328
相关内容
python爬虫爬取微博粉丝数据如何利用Python爬虫进行社交媒体数据挖掘
微博数据可视化分析:利用Python构建信息图表展示话题热度
可视化图形设计工具,数据可视化工具有哪些
Python怎么爬取娱乐圈的排行榜数据
Python数据可视化:3D图表大揭秘
python如何爬取123粉丝网明星数据榜单
hadoop 大数据毕业设计python+spark高考志愿填报推荐系统 高考用户画像系统 高考分数线预测系统 高考可视化 知识图谱 高考爬虫 计算机毕业设计 机器学习 深度学习 人工智能 数据可视化
利用Python进行数据可视化常见的9种方法!超实用!
八爪鱼和python爬虫哪个好
随便看看
最新实时动态
- 金敏喜 艺术家真的不在意世俗吗 这世界真的存在灵魂伴侣吗?
- 张凌赫又一秒惹怒金靖,姐姐起身瞬间他急忙伸手拉住,求生欲拉满了
- 胡歌新片抓特务演绎双面人生
- 付一笑再次遭到好兄弟背刺,夏静石向一笑求复和?
- 付一笑宣布锦绣三杰恩断义绝,宁非重伤命悬一线
- 谢三坦言心有所属,直言她与众不同
- 徐明浩谈好友相聚趣事,称男人聚一起智商变低
- 蒂姆现身兹维列夫基金会晚宴,或转型男团
- 汪苏泷称生活是创作灵感源泉
- 六少主重病生活艰难 妻子细心照料,不离不弃
热点实时动态
- 95413
- 24786
- 19389
- 19069
- 18843
- 18798
- 18526
- 18102
- 18063
- 18057

