数据挖掘与关联规则挖掘:算法解析与应用实例
01数据挖掘概述
数据挖掘是从大量数据中提取价值信息的过程,这一技艺正日益受到各行业的青睐。它涵盖了一系列精心设计的步骤,如定义和分析主题、数据预处理、算法选择、规则提取、结果评估与解释,以及最终将所发现的模式转化为实际可用的知识。其过程通常可概括为七个关键阶段。
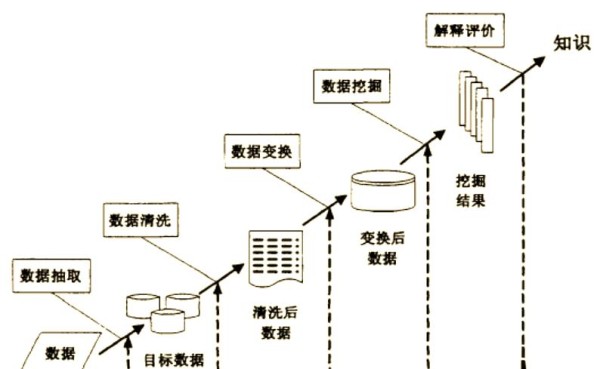
❒ 关键阶段
1、首先,需要清晰地设定数据分析的目标,以确保整个挖掘过程具有明确的方向。
2、接着,对数据进行谨慎的选择、组织和预处理,为后续的分析奠定坚实基础。
3、在完成数据准备后,进行探索性分析,深入了解数据的特征和潜在模式,并根据需要进行数据转换。
4、根据分析需求,确定在挖掘阶段将采用的具体方法,如聚类、分类、关联规则挖掘等。
5、运用选定的方法对数据进行深入分析,揭示数据中的有价值信息和模式。
6、对使用的方法进行评价和比较,选择最适合当前分析任务的分析模型。
7、最后,对所选模型进行解释,并探讨其在决策过程中的实际应用和价值。
02关联规则挖掘
❒ 概述和重要性
关联规则挖掘,简而言之,就是对存在关联关系的数据进行分析,以发现其中蕴含的关联规则。这种技术广泛应用于各个领域,例如,通过分析超市购物数据,可以发现某些商品之间的潜在联系,进而优化商品布局,提升销售业绩。
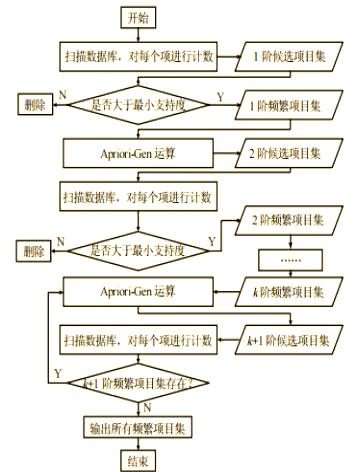
❒ Apriori算法细节
在数据挖掘领域,关联规则挖掘被视为一项关键技术。Apriori算法是一种用于挖掘频繁项目集的经典算法。它采用逐层搜索和迭代的方式,首先找出事务数据库中满足用户设定支持度阈值的频繁项集,然后基于这些频繁项集,进一步构造出满足最小置信度要求的关联规则。这种算法简单易懂,是数据挖掘领域中不可或缺的一环。
❒ 关键名词解释
在Apriori算法中,关键概念包括频繁项集、最小支持度和最小置信度。支持度表示数据组合频繁出现的概率,置信度表示其中的关联强度。具体来说:
1、最小支持度:在探索数据库中哪些数据具有关联性时,我们设定了一个关键数值,即最小支持度。这个数值不能过高也不能过低,它帮助我们判断哪些数据组合是频繁出现的,从而认为它们之间可能存在关联。具体来说,如果某规则A→B的支持度达到S,那么这意味着在所有事务中,包含A和B的百分比为S。
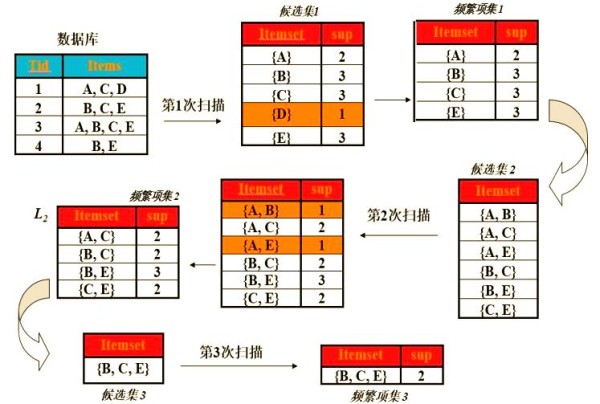
2、最小置信度:为了更准确地判断数据之间的关联性,我们引入了最小置信度的概念。仅仅依赖支持度来衡量关联性是不够的,因为这只能说明数据组合的频繁程度,而无法反映它们之间的实际关联强度。在A项集存在的情况下,我们进一步考察B项集的存在情况,如果A和B同时出现的概率较高,那么这种关联就不是偶然的。
当数据组合的支持度超过设定的最小支持度,并且置信度也超过最小置信度时,我们就认为该数据组合是强关联的。
❒ 剪枝策略和定律
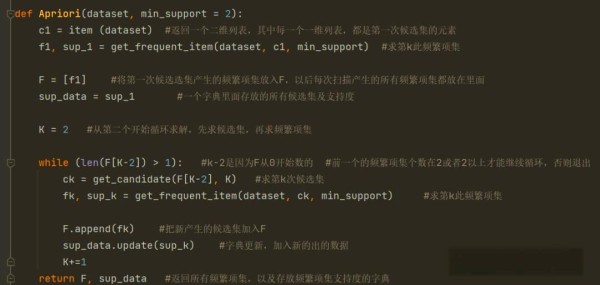
在关联规则挖掘的过程中,为了提升效率并减少不必要的计算,我们引入了剪枝策略。具体而言,设K为当前扫描的次数,当我们需要求取第K个候选集时,会回顾上一次扫描即第K-1次扫描所得到的频繁项集。不包含其(k-1)维子集的项集将被删除。
Apriori算法基于两个重要的定律:频繁项集的先验性质和交易数据库的逆向性质。
1)对于那些支持度低于最小支持度的数据组合,我们可以直接舍弃,因为它们的超集不可能是频繁项集。
2)如果一个集合被确定为频繁项集,即其支持度超过了预设的最小支持度,那么它的所有子集也都将被视为频繁项集。
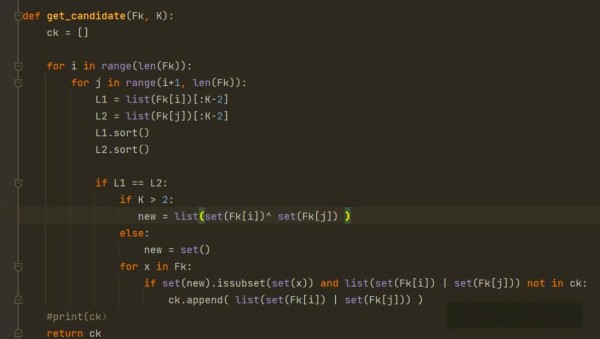
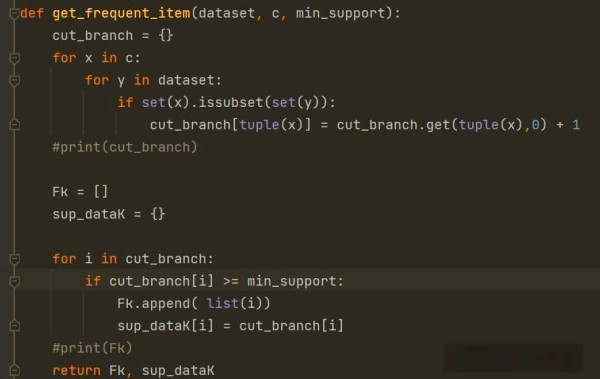
❒ 应用实例
接下来,我们将通过一个简单的实例来阐述Apriori算法的应用。基于上述所提及的概念,我们设定了四组数据:ACD、BCE、ABCE以及BE,并考虑五个不同的种类:A、B、C、D和E。算法的处理流程可参考以下图表。
最后,总结Apriori算法在挖掘频繁项集方面的特点及优化方向,以便更高效地应对实际应用的挑战。
网址:数据挖掘与关联规则挖掘:算法解析与应用实例 https://m.mxgxt.com/news/view/1443560
相关内容
数据挖掘与关联规则挖掘:算法解析与应用实例数据挖掘算法应用
大数据的常用算法(分类、回归分析、聚类、关联规则、神经网络方法、web数据挖掘)
数据挖掘6大常用算法详解
时空数据挖掘算法.docx
大数据挖掘算法实战:如何挖掘海量数据中的隐藏价值
娱乐行业数据挖掘与应用
关联规则和序列模式:挖掘数据中的隐藏模式
一文弄懂数据挖掘的十大算法,数据挖掘算法原理讲解
数据挖掘案例分析、经典案例、技术实现方案
随便看看
最新实时动态
- 美貌只是莱昂诺尔公主,最不值得一提的优点# 西班牙
- 秋风何时起…枯叶何时落…我君何时归?@丞磊 clclclclcl
- 母亲请小鬼助女成绩反遭反噬,女儿见同学身后皆有鬼
- 完全三个傻小子来的
- 红绸蒙眼名场面,萧无衣把命交谢嘉鱼
- 杨紫家业创作座谈会发言
- 周星驰透露功夫女足或有续作
- 电工为残疾父子修电路车陷河中,村民开拖拉机相助
- 人生顶配!家里一堆高颜值女儿,谁看了不说老爸值得一枚金牌
- 为什么爱情会消失的那么快,因为她根本没有真正爱过你
热点实时动态
- 118676
- 25441
- 20036
- 19719
- 19484
- 19440
- 19175
- 18744
- 18702
- 18694

