信息检索系统评估指标的层级分析:从单点精确度到整体性能度量
在构建搜索引擎系统时,有效的评估机制是保证系统质量的关键环节。当用户输入查询词如"machine learning tutorials python",系统返回结果列表后,如何客观评估这些结果的相关性和有效性?这正是信息检索评估指标的核心价值所在。
分析用户与搜索引擎的交互模式,我们可以观察到以下行为特征:
用户主要关注结果列表的前几项对顶部结果的关注度显著高于底部结果用户基于多次搜索体验形成对搜索系统整体质量的评价现代评估指标体系正是基于这些真实用户行为模式设计的,并且随着研究不断深入,评估方法也在持续演进以捕获更多细微交互特征。
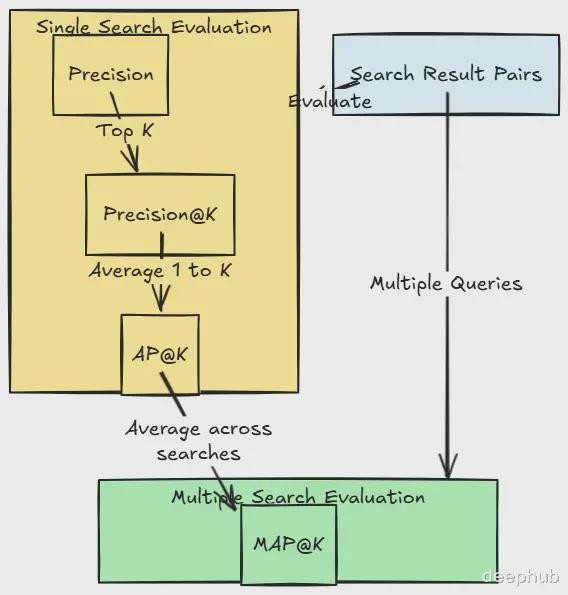
评估信息检索系统的精确度方法
评估框架的基本组成:预测结果与验证集
每次搜索评估涉及两个核心组成部分:
系统返回的预测相关结果集(系统检索结果)实际相关的结果集(人工标注的验证集或ground truth)以"best Python IDEs"的搜索为例:
系统返回结果(预测集):[PyCharm, VSCode, Sublime, Atom, Eclipse]实际相关结果(验证集):{PyCharm, VSCode, Jupyter, Spyder}下面构建一个评估框架来量化此类搜索的效果:
from typing import List, Set, Dict
from dataclasses import dataclass
@dataclass
class SearchEvaluation:
"""
Represents a single search evaluation.
predicted: Ordered list of items our search system returned
validation: Set of items that are actually relevant
"""
predicted: List[int]
validation: Set[int]
1、基础精确度指标
精确度(Precision)是最基本的评估指标,用于回答一个核心问题:"系统返回的结果中有多少比例是相关的?"
这一指标可类比为结果的正确率——若系统返回10个结果,其中7个与查询相关,则精确度为70%。
def precision(eval: SearchEvaluation) -> float:
"""
Calculate basic precision for a single search.
Real-world example:
predicted = [PyCharm, VSCode, Sublime, Atom, Eclipse]
validation = {PyCharm, VSCode, Jupyter, Spyder}
Result: 2/5 = 0.4 (40% precision)
"""
if not eval.predicted:
return 0.0
retrieved_set = set(eval.predicted)
relevant_retrieved = len(eval.validation.intersection(retrieved_set))
return relevant_retrieved / len(retrieved_set)
2、Precision@K:聚焦用户实际关注的范围
用户行为研究表明,搜索结果页面中,用户很少关注前几项以外的内容。如果系统在位置8、9和10返回相关结果,但在位置1-7提供不相关内容,那么从用户体验角度而言,这样的搜索效果并不理想。
Precision@K指标专注于评估前K个结果的精确度,这与实际用户行为模式更为匹配:
def precision_at_k(eval: SearchEvaluation, k: int) -> float:
"""
Evaluate precision for top-k results.
Real-world example:
For k=3:
predicted = [PyCharm, VSCode, Sublime, Atom, Eclipse]
validation = {PyCharm, VSCode, Jupyter, Spyder}
Only look at [PyCharm, VSCode, Sublime]
Result: 2/3 ≈ 0.67 (67% precision at k=3)
"""
if k <= 0 or not eval.predicted:
return 0.0
top_k = eval.predicted[:k]
return precision(SearchEvaluation(top_k, eval.validation))
3、Average Precision@K:考量位置权重因素
在K个结果集内部,不同位置的结果对用户的价值也存在显著差异。位置1的相关结果通常比位置3的相关结果更具价值。Average Precision@K (AP@K)通过在每个相关结果位置计算精确度并取平均值,有效地捕捉了这种位置权重效应:
def ap_at_k(eval: SearchEvaluation, k: int) -> float:
"""
Calculate position-aware precision up to position k.
Real-world example:
predicted = [PyCharm, Sublime, VSCode] (k=3)
validation = {PyCharm, VSCode}
Let's break it down:
Position 1 (PyCharm): 1/1 = 1.0 (found a relevant item)
Position 2 (Sublime): No change (not relevant)
Position 3 (VSCode): 2/3 ≈ 0.67 (found second relevant item)
AP@3 = (1.0 + 0.67) / 2 ≈ 0.835
"""
if k <= 0 or not eval.predicted:
return 0.0
precisions = []
num_relevant = 0
for i in range(min(k, len(eval.predicted))):
if eval.predicted[i] in eval.validation:
num_relevant += 1
precisions.append(num_relevant / (i + 1))
if not precisions:
return 0.0
return sum(precisions) / min(k, len(eval.validation))
4、MAP@K:系统整体性能评估
信息检索系统的评估不应局限于单一查询,而应考察系统在多样化查询场景下的整体表现。类似于不能仅凭一道菜评价一家餐厅的整体水平,搜索系统的质量评估也需要基于多样化的查询样本。
Mean Average Precision@K (MAP@K)通过对多个查询的AP@K值取平均,提供了系统层面的综合性能指标:
def map_at_k(evaluations: List[SearchEvaluation], k: int) -> float:
"""
Evaluate overall system performance across multiple searches.
Example scenario:
Search 1: "python ide" → AP@3 = 0.835
Search 2: "python web frameworks" → AP@3 = 0.92
Search 3: "python data science" → AP@3 = 0.76
MAP@3 = (0.835 + 0.92 + 0.76) / 3 ≈ 0.838
"""
if not evaluations:
return 0.0
ap_scores = [ap_at_k(eval, k) for eval in evaluations]
return sum(ap_scores) / len(evaluations)
实际应用案例分析
以下是一个小型搜索系统的评估示例:
# Sample searches
searches = [
# Search: "python ide"
SearchEvaluation(
predicted=[1, 2, 3, 4, 5], # 1=PyCharm, 2=VSCode, etc.
validation={1, 3, 5} # PyCharm, Sublime, Eclipse are relevant
),
# Search: "python web frameworks"
SearchEvaluation(
predicted=[2, 4, 1, 3, 5], # 2=Django, 4=Flask, etc.
validation={1, 2, 3} # Django, Flask, FastAPI are relevant
),
]
k = 3 # We care about top 3 results
# Evaluate individual searches
for i, search in enumerate(searches, 1):
print(f"Search {i}:")
print(f" Precision@{k}: {precision_at_k(search, k):.3f}")
print(f" AP@{k}: {ap_at_k(search, k):.3f}")
# Evaluate overall system
print(f"\nOverall System MAP@{k}: {map_at_k(searches, k):.3f}")
核心结论与应用价值
这些评估指标体系呈现出层级递进的关系,提供了逐步深入的质量评估维度:
精确度(Precision)提供基础的质量评估分值Precision@K认可并量化了用户对顶部结果的关注倾向AP@K通过位置加权机制优化了排序质量评估MAP@K确保了系统在多样化查询场景下的一致性表现值得注意的是,高质量的信息检索系统需要在这些指标的各个层面都表现优异,正如一家优质餐厅需要在从前菜到甜点的全部菜品中保持水准。
这些评估指标的核心价值在于它们高度契合实际用户行为模式:我们更关注前几个结果(Precision@K),重视结果的合理排序(AP@K),并且期望系统在各类查询中保持稳定性能(MAP@K)。这种多维度的评估体系为信息检索系统的持续优化提供了科学的指导框架。
https://avoid.overfit.cn/post/d523489195124d5c9b60552d0df54fb3
作者:Raj Arun
特别声明:以上内容(如有图片或视频亦包括在内)为自媒体平台“网易号”用户上传并发布,本平台仅提供信息存储服务。
Notice: The content above (including the pictures and videos if any) is uploaded and posted by a user of NetEase Hao, which is a social media platform and only provides information storage services.
网址:信息检索系统评估指标的层级分析:从单点精确度到整体性能度量 https://m.mxgxt.com/news/view/1271944
相关内容
信息检索系统:从理论到实践信息检索系统
中电建路桥申请基于可拓云模型的梁场系统韧性评估方法专利,可对定性和定量指标进行更合理分析
文献检索系统
从明星八卦到深度分析:这信息量真的好大!
CT和MRI定量评估腹部脂肪与非酒精性脂肪肝严重程度的相关性研究
搜索指数:精准内容与用户热度分析新功能详解
如何建立客户忠诚度指标的监测系统?
微信公众号粉丝量分析:如何评估公众号价值
剖析智能宠物领域的领军者Homeika、Petkit,Funnyfuzzy,从社交媒体策略与KOL营销角度分析 – 出海指南
随便看看
最新实时动态
- 越品越心疼慕容清渝,一生困于家族束缚,最后用性命给出最热烈的偏爱
- 两个爱尔兰疯子血洗黑帮,以暴制暴才是最解气的正义!
- 将门独后:好美好透亮 每个镜头都妙不可言
- 我要笑晕了被通知要麦麸突然露出了“卧槽居然轮到我们下海了?”的表情
- 周佑凌凝视柳柳双眼 告白夜爱意充盈宇宙
- 2026|0729|文轩 《米爆探班日记》EP03 ▷
- 赵昭仪在《御廷谣》里的演技和台词被嘲了
- 吴谨言陈哲远新剧,科考成绩被顶替状告公堂
- 周星驰张柏芝为李昊红馆演唱会送花篮
- 陆江来拒绝认亲,只看将来不问过往
热点实时动态
- 140635
- 25556
- 20144
- 19836
- 19577
- 19538
- 19265
- 18845
- 18823
- 18792

